La mayor parte de los análisis de sensibilidad publicados son erróneos
Imagina el modelo matemático de un proceso - como por ejemplo el rendimiento de una reacción química o el flujo que pasa por un acuífero- que produce una salida diferente -como puede ser la cantidad de una sustancia química o el flujo de agua , para seguir con los ejemplos -que depende de cada una de las combinaciones de las variables de entrada. Estas variables podrían ser las características de los reactivos químicos o de la hidrología de la cuenca en nuestros ejemplos.
Imagina también que las variables de entrada son inciertas, es decir, que pueden tomar diferentes valores o bien porque son desconocidos (el hecho de que el ratio de la reacción química no se conozca con precisión, en el ejemplo) o bien porque suelen variar en la naturaleza (como puede ser la intensidad de la precipitación que alimenta el acuífero). Hay, entonces, un número infinito de posibles combinaciones de variables de entrada que dan cada valor diferente de salida.
Mediante la aplicación del modelo matemático un número suficiente de veces, se puede tener una idea de cómo se distribuyen los valores de salida, es decir, cuál es su media, su varianza, etc. Este procedimiento se denomina habitualmente "análisis de incertidumbre", ya que investiga la incertidumbre de los valores de salida. En este sentido, uno puede preguntarse si todas las variables de entrada tienen el mismo peso sobre el grado de incertidumbre de las salidas. De hecho, esto no ocurre casi nunca, por lo que a menudo muchas de las variables de entrada pueden modificar completamente el valor de salida con un pequeño cambio en los valores de las entradas, al tiempo que unas pocas variables dominan el carácter del proceso. A este campo de investigación se le denomina "análisis de sensibilidad", ya que investiga cómo las salidas son sensibles a las variables de entrada en un determinado proceso. Un análisis de sensibilidad puede conducir a declaraciones como "el 70% de la varianza del valor de salida es causada por el factor X4, el factor X2 causa el 25% de la varianza, y el restante 5% es causado por otros factores".
Sorprendentemente, la mayor parte de los análisis de sensibilidad (por lo que parece, 96 de cada 100 en el año 2014, según nuestro estudio) sufren un gran defecto, hasta el punto de ser inútiles. No combinan todos los valores de entrada y dejan inexplorada una larga fracción, o bien casi totalidad, de las posibles combinaciones.
¿Cuál es el procedimiento que conduce hacia este resultado tanto decepcionante? El procedimiento, sólo adecuado en apariencia, es el siguiente. En primer lugar, calcular el valor de salida en correspondencia a un punto central donde todas las variables tienen su "estimación más probable" o "más adecuada". Y, a continuación, alejar cada variable de este estándar central y calcular el valor de salida para usar esta diferencia como una medida de sensibilidad.
Todo esto parece lógico pero sus resultados sólo son buenos si el modelo es lineal. Cuando el modelo no lo es, pueden suceder cosas interesantes cuando más de una variable se mueve lejos de su valor central. Por poner un ejemplo, una reacción química puede convertirse en explosiva para una combinación particular de entradas, lo que no puede apreciar el procedimiento que acabamos de describir. Así, un análisis de sensibilidad hecho de esta manera produciría un ranking inválido sobre los factores de entrada. Se podrían, por ejemplo, obviar factores que son primordiales. Esto es bien conocido y trivial por los estadísticos y por quienes llevan a cabo análisis de sensibilidad, al tiempo que sigue siendo pasado por alto por la mayoría de agentes dedicados a la construcción de modelos de análisis.
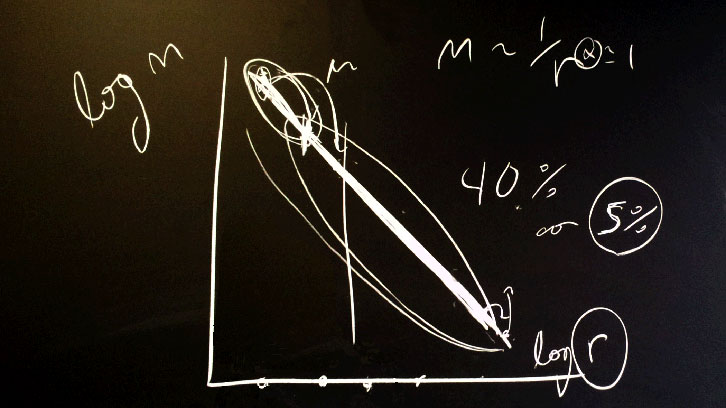
Utilizando un argumento geométrico, nuestro artículo de investigación muestra que el típico análisis de sensibilidad de 10 factores deja inexplorado el 99,75% de las posibles combinaciones de valores. Esto equivale a un estado total de ceguera cuando se equipara con el potencial del modelo si se le permite mover con libertad, en lugar de estar atado en el centro de sus valores de factor de entrada.
Para un procedimiento correcto se deberían distribuir los puntos lo más uniformemente posible dentro del espacio donde todas las combinaciones del valor de los parámetros fueran posibles.
Referencias
Ferretti, F., Saltelli A., Tarantola, S., Trends in Sensitivity Analysis practice in the last decade, Science of the Total Environment. 2016. Special issue on Human and biota exposure. DOI: 10.1016/j.scitotenv.2016.02.133